by megalab.it
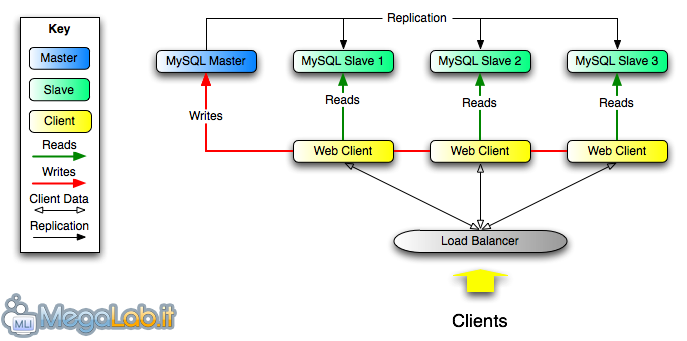
MySQL consente di “fotocopiare” i database gestiti da un singolo server principale su molteplici server secondari: un’ottima soluzione per distribuire il carico oppure per approntare una procedura di backup efficiente ed automatica.
Quando il carico sull’infrastruttura inizia a divenire elevato, affiancare un secondo server a quello principale è pressochè un obbligo per rimanere operativi.
Anche la versione “community” di MySQL (ovvero quella gratuita) offre una comoda funzione di replicazione che consente di “fotocopiare” in maniera del tutto automatica i dati immessi sul primo server anche sull’altro(oppure “sugli altri”, in caso le macchine impiegate siano più numerose).
In più, il tutto funziona in modo asincrono: questo significa che nella circostanza in cui i server secondari siano impossibilitati ad aggiornarsi per diverso tempo (ad esempio, a causa di un guasto hardware o per la temporanea mancanza di connettività), il database verrà automaticamente ri-allineato non appena il problema sarà risolto.
L’operazione è chiamata replicazione (replication) e in questo articolo vedremo come predisporla.
Terminologia: “master” e “slave”
Prima di iniziare, puntualizziamo la terminologia. In ambito di replicazione, si parla di server “master” e di server “slave”.
Il “master” è il database che possiamo definire “primario”: è su di esso, e solo su di esso!, che dovranno essere effettuate le operazioni di scrittura (INSERT/UPDATE/DELETE ecc). Tutte le modifiche apportate ai dati memorizzati sul master saranno poi replicate sugli altri server secondari.
I server secondari sono chiamati “slave”: il loro compito è quello di erogare i dati in sola-lettura e di recuperare in maniera automatica tutte le novità immesse sul master associato.
Vi possono essere molteplici slave collegati ad un singolo master, ma non più di un solo master collegato ad ogni slave. In altre parole, è possibile replicare i dati su molteplici server secondari, ma ognuno di essi può mantenersi allineato ad un solo master.
Di cosa avete bisogno
Prima di iniziare la configurazione dovete controllare che la porta di MySQL in esecuzione sul master (si tratta della 3306 TCP, se avete mantenuto le impostazioni di default) sia aperta e raggiungibile dagli slave. Potete verificarlo tentando di connettervi dall’esterno mediante il client a linea di comando (mysql -uNomeUtente -pMiaPassword -hIndirizzoMaster, ricordando che, per impostazione predefinita, l’utente root non è abilitato alle connessioni remote) oppure con uno strumento di port-scanning come Nmap.
Dovete inoltre disporre di almeno due server distinti (un master e uno slave), ed avere pieno accesso ad entrambi.
Su ognuno di essi dovrà poi essere in esecuzione un’istanza di MySQL. In questa sede darò per scontato che il programma sia già installato e configurato: per maggiori informazioni circa il setup su Windows, si veda “Trasformare il PC in un server HTTP con Apache, PHP, MySQL e Perl“.
Non è necessario che i server utilizzino la stessa piattaforma: potete replicare senza problemi un master Linux su uno slave Windows (o viceversa), anche in caso un sistema operativo sia a 32 bit e l’altro a 64 bit (o viceversa).
Non è nemmeno richiesto che la versione di MySQL sia la medesima: la replicazione tollera una o due minor release (il numero dopo il punto) di differenza. È comunque altamente raccomandabile usare sempre le ultime build disponibili su entrambi i sistemi.
Configurazione del master
Per prima cosa, ci occuperemo di predisporre il server master. Aprite quindi il relativo file di configurazione di MySQL sulla macchina principale.
Se state operando sotto Windows, tale file si trova nella cartella d’installazione del programma stesso: per impostazione predefinita, C:\Programmi\MySQL\MySQL Server <versione>\my.ini.
Se invece il vostro sistema utilizza Linux… individuare il corrispondente my.cnf è meno immediato, poichè il percorso varia da distribuzione a distribuzione. /usr/local/mysql/ potrebbe essere un buon candidato. In caso ancora non lo troviate, aiutatevi con find / -name "my.cnf".
Una volta aperto il file, individuate la sezione [mysqld] . Fate attenzione: è presente anche una sezione[mysql] (senza la “d” finale) che, però, non è quella che ci interessa!
Una volta trovata la linea giusta, modificatela aggiungendo subito sotto due parametri, così come indicato di seguito
[mysqld]
log-bin=mysql-bin
server-id=1Il risultato dovrà essere quello riportato in immagine
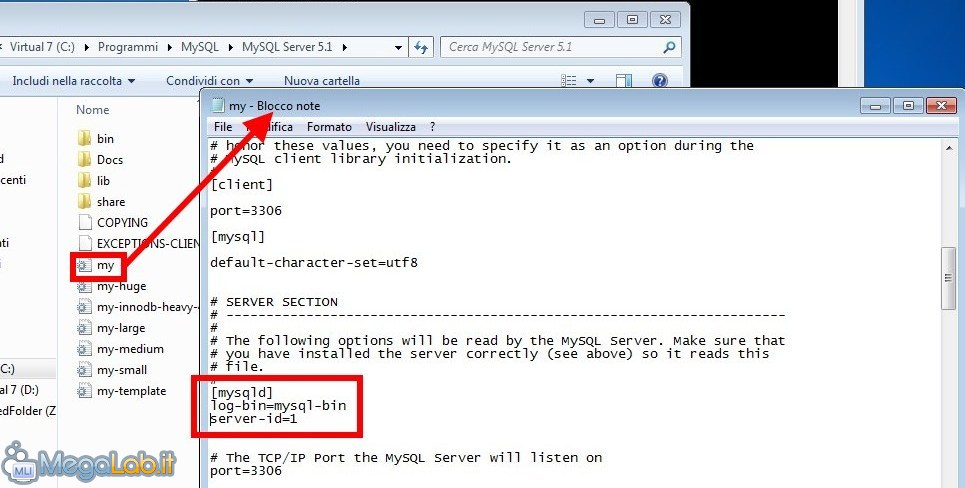
Dopo aver apportato tale variazione, salvate la modifica. Notate che, su Windows Vista e successivi con Controllo Account Utente (UAC) attivo, dovrete dapprima salvare il documento in una cartella non-“di sistema” come il desktop, quindi sovrascrivere manualmente il vecchio file con quello nuovo.
Riavviate ora il database: se MySQL è installato come servizio di sistema (impostazione predefinita), aprite unprompt di comando amministrativo e quindi lanciate net stop mysql seguito da net start mysql. Sotto Linux usate semplicemente service mysqld restart.
Creare un account per la replicazione
I vari slave dovranno accedere al server presentando credenziali d’accesso valide. Sebbene qualsiasi utente dotato di un certo privilegio possa essere usato, raccomando vivamente di creare un account adibito alla sola replicazione dei dati.
Per farlo, accedete al database del master (mysql -uNomeUtenteAmministratore -pRelativaPassword se lavorate da linea di comando) e quindi impartite CREATE USER 'Replicator'@'%' IDENTIFIED BY 'RepliCarter';.
Appare evidente che il nome utente scelto, Replicator, e la relativa password, RepliCarter (se non capitel’ironia, è normale..) sono del tutto arbitrari.
Una volta creato l’utente, impartite GRANT REPLICATION SLAVE ON *.* TO 'Replicator'@'%';: questo doterà l’account di replicazione dell’unico privilegio necessario ad operare.
Notate che REPLICATION SLAVE deve essere obbligatoriamente assegnato all’intero server. Tentare di limitarlo ad uno specifico database, con qualcosa simile aGRANT REPLICATION SLAVE ON miodatabase.* TO 'Replicator'@'%'; restituirà, per qualche motivo che va ben oltre la mia comprensione, un errore.
Gli amministratori di sistema più cauti vorranno limitare al solo indirizzo dello slave la possibilità di autenticarsi con tale account. Per farlo, è sufficiente sostituire (in entrambi i comandi) a 'Replicator'@'%' la stringa 'Replicator'@'192.168.0.75' o 'Replicator'@'192.168.0.%' (per tutta la rete locale) oppure'Replicator'@'slave.miodominio.it' o 'Replicator'@'%.miodominio.it' (per tutto il dominio).
Preparasi a qualche disagio
Il prossimo passaggio inibirà per qualche tempo le operazioni di scrittura sul database. Più precisamente, tutti i tentativi di modificare i dati verranno posti in attesa fino alla fine dell’operazione: questo potrebbe comportare qualche timeout o altri tipi di disagi per gli utenti della base di dati.
Se la vostra applicazione è predisposta per consentire l’uso del servizio anche in sola-lettura, potete facilmente attenuare l’inconveniente agendo su questa caratteristica.
In caso contrario, il consiglio è quello di prevenire completamente tali problemi inibendo del tutto l’accesso al database. Se MySQL funge unicamente da backend ad un sito web, il risultato si può ottenere facilmente arrestando il server HTTP. In caso contrario, lo scenario è più complesso e sarà necessario ragionare caso per caso.
Generare una copia del database per i client
Dovete ora “fotocopiare” manualmente il contenuto del master sullo slave.
Per farlo, useremo mysqldump sul master, per poi importare il file da esso generato sul server secondario.
Il comando da usare (all’interno di un prompt di comando amministrativo) per “dumpare” i tre database di nome miodatabase è mysqldump -uroot -pmiapassword --databases miodatabase1 miodatabase2 miodatabase3 --add-drop-database --master-data > C:\dump_del_database_master.sql (sotto Linux è necessario solamente sostituire C:\ con un percorso adeguato al file system, come /usr/).
Prestate particolare attenzione a non dimenticare il parametro --master-data del comando! Questo semplifica moltissimo la procedura e, per come è stato impostato il discorso fino ad ora, è indispensabile per mantenere integri i dati esportati.
Notate anche che, sempre per garantire l’integrità dei dati, dovrete indicare nel comando tutti i nomi dei database che vorrete poi replicare.
La vostra priorità è ora probabilmente quella di ripristinare la piena operatività del server. Potete procedere non appena l’operazione di dump si sarà conclusa.
A questo punto, trasportate il file generato da mysqldump sullo slave (FTP, SCP, Desktop Remoto… perfino un servizio di filehosting va benissimo, se siete disperati e poco preoccupati della riservatezza delle informazioni) e tenetelo pronto: servirà fra poco.
Per una trattazione più approfondita di mysqldump si veda l’articolo “Guida rapida al backup e ripristino dei database MySQL“.
Il master è di nuovo operativo e sta funzionando come di consueto. Possiamo quindi dedicarci alla configurazione dei server secondari.
Configurare il primo “slave”
Aprite il file di configurazione di MySQL sul primo server slave.
Se state operando sotto Windows, tale file si trova nella cartella d’installazione del programma stesso: per impostazione predefinita, C:\Programmi\MySQL\MySQL Server <versione>\my.ini.
Se invece il vostro sistema utilizza Linux… individuare il corrispondente my.cnf è meno immediato, poichè il percorso varia da distribuzione a distribuzione. /usr/local/mysql/ potrebbe essere un buon candidato. In caso ancora non lo troviate, aiutatevi con find / -name my.cnf.
Una volta aperto il file, individuate anche qui la sezione [mysqld]. Nuovamente, vi raccomando di tenervi alla larga dalla sezione [mysql] (senza la “d” finale), poichè non è quella che ci interessa.
Una volta individuata la giusta riga, aggiungetevi subito sotto i parametri proposti di seguito:
[mysqld]
server-id=2
replicate-wild-do-table=miodatabase1.%
replicate-wild-do-table=miodatabase2.%
replicate-wild-do-table=miodatabase3.%Sostituite, naturalmente, a miodatabase1, miodatabase2 e miodatabase3 i nomi dei database che vorrete replicare dal master.
Ricordate soltanto di utilizzare una riga distinta per ogni database.
Se ometterete di specificare almeno un database, l’intero contenuto del server master (compresa la tabella “di sistema” chiamata mysql) verrà replicato.
Per garantire la massima integrità dei dati, vi raccomando inoltre di non richiedere in questo modo la replica di un database che non sia stato precedentemente incluso nel dump generato sul master.
Dopo aver apportato tale variazione, salvate la modifica. Notate che, su Windows Vista e successivi con Controllo Account Utente (UAC) attivo, dovrete dapprima salvare il documento in una cartella non-“di sistema” come il desktop, quindi sovrascrivere manualmente il vecchio file con quello nuovo.
Riavviate ora il database: se MySQL è installato come servizio di sistema (impostazione predefinita), aprite unprompt di comando amministrativo e quindi lanciate net stop mysql seguito da net start mysql. Sotto Linux usate semplicemente service mysqld restart.
Da dove prendo i dati?
Dovrete ora indicare allo slave le coordinate necessarie per collegarsi con il server master e recuperare, di volta in volta, i vari aggiornamenti.
Accedete al database dello slave (mysql -uNomeUtenteAmministratore -pRelativaPassword se lavorate da linea di comando) e quindi impartite CHANGE MASTER TO MASTER_HOST='master.miodominio.it', MASTER_USER='Replicator', MASTER_PASSWORD='RepliCarter';.
Come è ovvio, immettete come valore di MASTER_HOST l’indirizzo del vostro server master (va benissimo anche l’indirizzo IP). Gli altri due parametri devono invece riportare le credenziali d’accesso per l’utente abilitato alla replicazione creato precedentemente sul master.
Importare il database “dumpato”
Aprite un nuovo prompt di comando ed impartite mysql -uNomeUtenteAmministratore -pReplativaPassword < C:\dump_del_database_master.sql, indicando, naturalmente, il file generato in precedenza da mysqldump sul master.
Gli utenti Linux, ovviamente, devono usare un percorso adeguato al proprio file system.
Attivare la sincronizzazione
Ad operazione terminata, aprite nuovamente lo strumento di gestione di MySQL (mysql -uNomeUtenteAmministratore -pRelativaPassword se lavorate da linea di comando) e quindi impartite semplicemente START SLAVE;.
Sebbene nessuna informazione sia mostrata a video, i dati locali dovrebbero iniziare a sincronizzarsi automaticamente con il master remoto: il modo migliore di verificarlo è quello di apportare qualche variazione ai dati sul database master e controllare che vengano recepiti anche sullo slave.
In caso tutto funzioni correttamente, non resta che premiarsi con un po’ di relax! In caso contrario…
Cosa fare se qualcosa non funziona
Se l’operazione non funziona come dovrebbe, non resta che rimboccarsi le maniche e cercare di risalire alla causa.
MySQL mantiene un file con estensione .err e lo stesso nome del sistema locale. All’interno dello stesso, il programma segnala con grande chiarezza i vari errori, compresi i motivi che hanno impedito la sincronizzazione. La posizione predefinita di tale log dipende dal sistema in uso.
Se state operando sotto Windows XP o Windows Server 2003, aprite il percorso %ALLUSERSPROFILE%\Dati applicazioni\MySQL\MySQL Server <versione>\data .
Sotto Windows Vista o Windows Server 2008 e successivi invece, %ALLUSERSPROFILE%\MySQL\MySQL Server <versione>\data .
Su taluni sistemi Linux, provate invece in /usr/local/mysql/data o ricorrette alle funzioni di ricerca del sistema operativo.
Una volta aperto il file .err, troverete un messaggio che vi illustrerà la natura del problema.
Nel corso delle mie prove, l’unico in cui mi sono imbattuto è stato [ERROR] Slave I/O: error connecting to master: questo significa che lo slave non è riuscito a contattare il master. Nel mio specifico caso, si era trattato semplicemente di un errore nella configurazione del firewall.
Per tutti gli altri inconvenienti, la ricerca con Google dovrebbe aiutarvi. In caso contrario, inserite un commento e la community di MegaLab.it cercherà di darvi una mano.
Configurare gli altri “slave”
Se avete la necessità di configurare altri server slave oltre al primo (complimenti! la vostra infrastruttura è davvero bella grossa!) ripetete l’operazione descritta nella pagina che avete davanti anche su tutte le altre macchine che volete adibire a slave.
È tutto esattamente uguale, non fosse per l’identificativo server-id immesso nel file di configurazione, che dovrà essere ben distinto per ogni sistema: in altre parole, nel file di configurazione del secondo slave si scriverà server-id=3, sul terzo server-id=4 e via dicendo.
Non è necessario che la numerazione sia progressiva, ma è sicuramente una buona idea per non fare confusione e semplificare eventuali operazioni di sostituzione.
Il backend è pronto: ora tocca ai programmatori
Ormai è quasi tutto pronto dal punto di vista del backend. Prima di aprire le porte dello slave al pubblico però, è generalmente indispensabile eseguire qualche adattamento al codice dell’applicazione.
In particolare, ricordate che tutte le scritture (quindi inserimenti, aggiornamenti ma anche cancellazioni e modifiche alla struttura del database e della tabelle) dovranno essere rivolte al server master.
Non bisognerà mai operare direttamente sugli slave: come già ricordato, tali server dovranno funzionare unicamente in lettura.
Il codice dovrà essere modificato di conseguenza, utilizzando connessioni differenti per le letture e le scritture.
Attenzione al ritardo!
Nell’adattare l’applicazione al modello replicato, i programmatori dovranno tenere ben presente che non v’è nessuna garanzia in merito ai tempi di replicazione. A meno di carico elevato, il tutto si sbriga generalmente in meno di un secondo… ma il modello asincrono comporta che il ritardo con il quale gli slave ricevono gli update dai client non sia prevedibile a priori.
Sarà quindi necessario fare attenzione a questo aspetto in fase di progettazione e predisporre gli opportuni controlli.
Garantire che gli slave operino in sola-lettura
Suggerisco di garantirsi la certezza che gli slave non subiscano operazioni di scrittura revocando tutti i privilegi di accesso ai vari utenti del database, per poi riconcedere solo quelli di lettura. I comandi utili allo scopo sono:
REVOKE ALL PRIVILEGES, GRANT OPTION FROM 'NomeUtente'@'%';
GRANT SELECT ON miodatabase.* TO 'NomeUtente'@'%';
Tali istruzioni vanno ripetute per ogni account presente sul database.
Due parole sulla sincronizzazione bi-direzionale (“multi-master”)
Durante le ricerche necessarie ad approntare questo articolo mi sono imbattuto in alcune guide che suggeriscono come implementare un’infrastruttura ibrida nella quale i server si sincronizzano in maniera bi-direzionale.
Questo ha l’indubbio vantaggio di consentire le scritture su entrambi i sistemi, ma espone anche uno svantaggio significativo: non è una modalità prevista ufficialmente da MySQL.
Di più: il manuale sconsiglia apertamente tale scenario: amenochè non sia la logica dell’applicazione stessa a farsi carico di alcune operazioni di allineamento tutt’altro che banali, vi è il rischio concreto che possa verificarsi una corruzione dei dati.
Chi avesse tale necessità farebbe quindi meglio ad abbandonare la versione standard di MySQL e passare per prima cosa a MySQL Cluster. Fatto ciò, il punto di partenza per la replicazione bidirezionale diviene il capitolo17.6.10 del manuale ufficiale.
Rescindere il legame
Se, per qualsiasi motivo, avete la necessità di rescindere il legame fra slave e server, è sufficiente lanciare questi comandi sullo slave:
STOP SLAVE;
RESET SLAVE;
Ricordate che questo trancia del tutto ogni rapporto fra i due calcolatori. Per ripristinarlo, sarà necessario ripetere nuovamente tutta la configurazione dello slave.Allo scopo, potete comunque ri-utilizzare lo stesso file di dump generato in precedenza, se l’avete conservato.
Riferimenti
Questa guida è solo un’introduzione ad un argomento, quello della replicazione dei dati fra più server MySQL, davvero ampio.
Se siete arrivati fino a qui, avrete ottenuto un’infrastruttura funzionante ed in grado di essere realmente utile in ambienti di produzione, ma che può sicuramente essere perfezionata.
Il punto di partenza per approfondire il discorso è la corposa sezione “Chapter 16. Replication” del manuale ufficiale del software.
In particolare, raccomando di dare un’occhiata al capitolo 16.3.7, nel quale è illustrato come abilitare la connessione crittografata SSL fra master e slave: tale opzione non ha troppo senso se le due macchine fanno parte della stessa LAN, ma può invece risultare importante in caso il master propaghi agli slave dati riservati attraverso Internet.
Un altro capitolo di sicuro interesse è il 16.3.6: in esso viene mostrato come, sebbene non proprio in maniera lineare, “promuovere” uno slave a server principale in caso il master originale divenisse inservibile.